Extracting High Interest Moments
Search that makes you Feel Something
When is the last time that a Google search made you feel ‘all warm and fuzzy’?
Sometimes you hear a voice, and it makes you feel like you have a home.
Radio was called “the companionship model” for a reason. Hosts become a part of our lives because we want to be given information and learn and be entertained by humans, not robots, not links on a page. We crave familiar, reliable sources of support. We crave the human voice.
So what if the delivery of information started to have more human in it, rather than less?
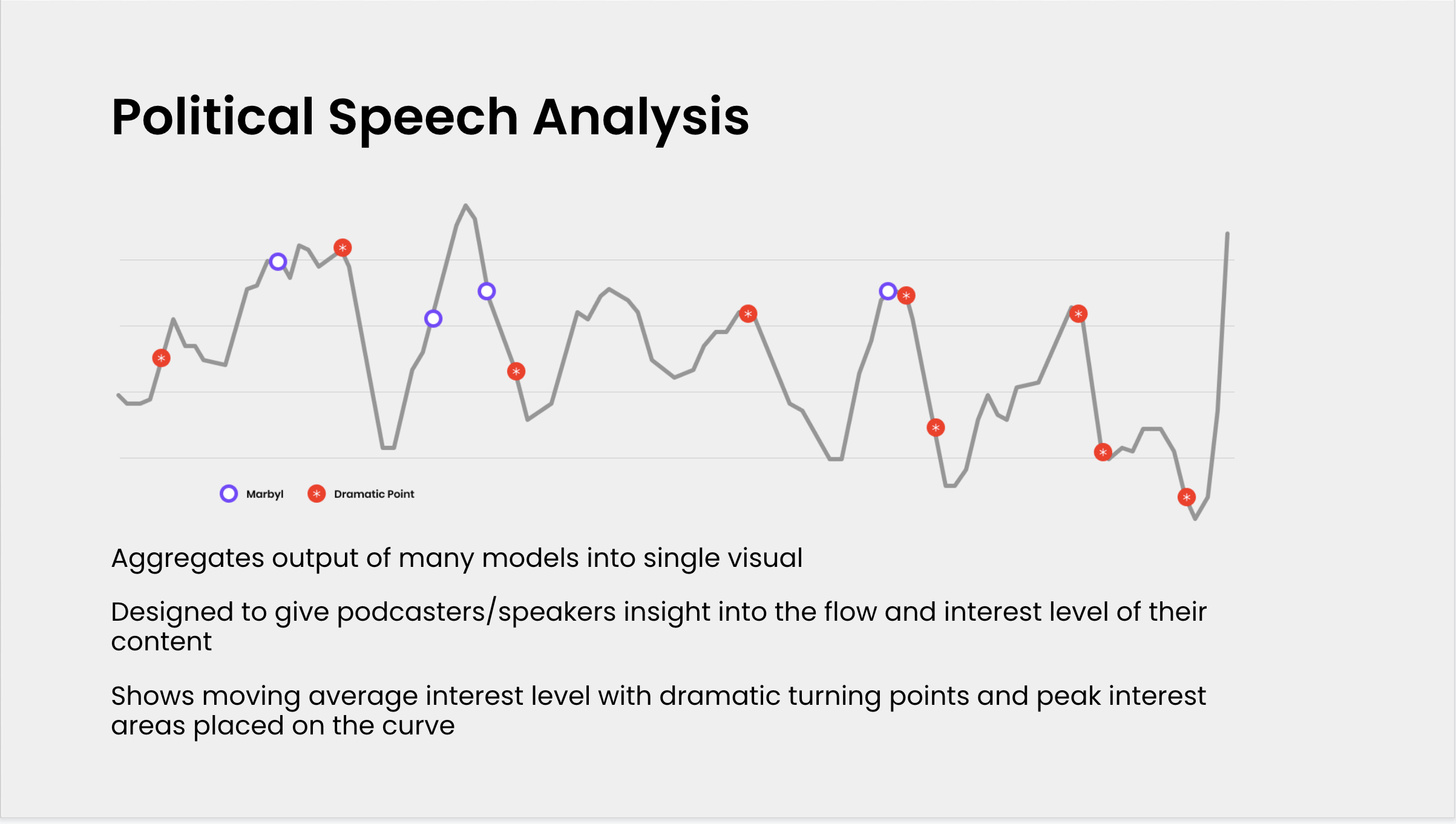
We’ve built the technology that knows how to identify the regions most likely to have someone feel something from within spoken dialogue.
The AI we’ve invented understands "interest level" and what regions of spoken dialogue are packed with "viral attributes". Afterall, things that "go viral” are things that make someone feel something enough to want to share it.
We have a complexity of all in-house developed and patented models that overlap and interact to extract and package these areas of content and make them accessible through search, as well as shareable anywhere.
Words from our CTO
“The Treegoat ML/AI team has developed ground-breaking models for identification of high interest moments in podcasts and other audio. Our models are continuously refined to ensure the user experience built on the data our models provide is engaging and appropriate to user interests.
To date, we have developed general purpose models for determining interest level as well as genre specific models that identify dramatic turning points and degrees of objectivity/subjectivity, to name a few. Through the precise application of multiple custom models, Treegoat is able to provide unrivaled experiences for content identification, context sensitive search, and interest-based recommendations that can be applied across multiple media types and industries.”
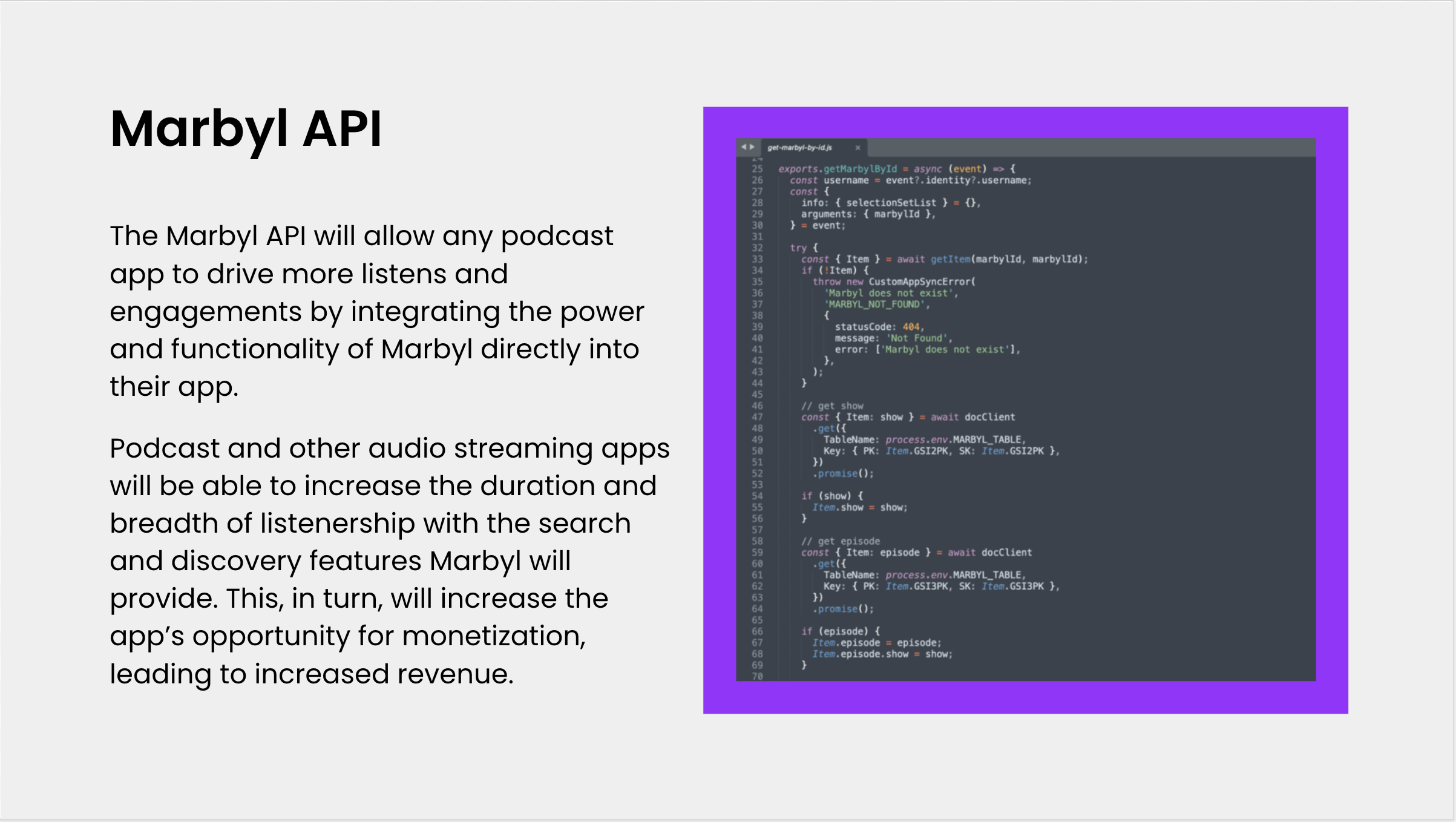
The first application of our technology is what fuels Marbyl:

Marbyl's unique models are capable of identifying interesting moments without the need for continued manual labeling of data nor significant analysis of podcast transcript data to successfully isolate themselves.